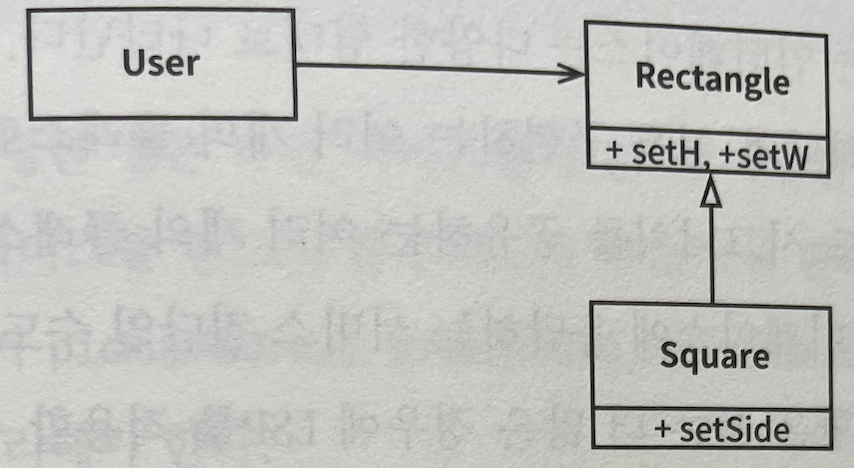
DIP
- 유연성이 극대화된 시스템 : 소스 코드 의존성이 추상(Abstraction)에 존재하며 구체(Concretion)에는 의존하지 않는 시스템
자바와 같은 정적 타입 언어에서 이 말은 user, import, include 구문은 오직 인터페이스나 추상 클래스 같은 추상적인 선언만 참조해야 한다는 뜻이다.
루비나 파이썬과 같은 동적 타입 언어에도 동일한 규칙이 적용된다.
BUT 이 아이디어를 규칙으로 보기는 확실히 비현실적이다.
SW 시스템이라면 구체적인 많은 장치에 반드시 의존하기 때문이다.
-> EX) 자바에서는 String은 구체 클래스이며, 이를 추상클래스로 만들지도 못한다.
java.lang.String 구체 클래스에 대한 소스 코드 의존성은 벗어날 수 없고, 벗어나서도 안된다.
반면 String 클래스는 매우 안정적이다.
String 클래스가 변경되는 일은 거의 없으며, 있더라도 엄격하게 통제된다.
프로그래머는 String 클래스에서 변경을 고려하지 않아도 된다.
*이러한 이유로 DIP를 논할 때 OS나 플랫폼 같이 안정성이 보장된 환경에 대해서는 무시하는 편이다.
-> 우리가 의존하지 않도록 하는 것은 변동성이 큰 구체적인 요소다.
-> 이 구체적인 요소는 우리가 열심히 개발하는 중이라 자주 변경될 수밖에 없는 모듈이다. *
안정된 추상화
추상 인터페이스에 변경이 생기면 이를 구현한 구현체들도 수정해줘야 한다.
반대로 구현체에 변경이 생기더라도 인터페이스는 대다수 변경될 필요가 없다.
-> 인터페이스는 구현체보다 변동성이 낮다.
안정된 SW 아키텍처란 변동성이 큰 구현체에 의존하는 일은 지양하고
안정된 추상 인터페이스를 선호하는 아키텍처라는 뜻이다.
구체적인 코딩 실천법
- 변동성이 큰 구체 클래스를 참조하지 말라
- 대신 추상 인터페이스를 참조하라
- 이 규칙은 언어가 정적/동적 관계없이 적용된다.
- 객체 생성 방식을 강하게 제약하며, 일반적으로 추상 팩토리를 사용하도록 강제한다
- 변동성이 큰 구체 클래스로부터 파생하지 말라
- 이전 규칙의 이어진 정리
- 상속은 소스 코드에 존재하는 모든 관계 중 가장 강력한 동시에 뻣뻣해서 변경이 어렵다.
- 따라서 상속은 아주 신중하게 사용해야 한다.
- 구체 함수를 오버라이드 하지 말라
- 대체로 구체함수는 소스 코드 의존성을 필요로 한다.
- 따라서 구체 함수를 오버라이드하면 이러한 의존성을 제거할 수 없고, 그 의존성을 상속하게 된다.
- 의존성을 제거하려면, 추상 함수로 선언하고 구현체들에서 각자의 용도에 맞게 구현해야 한다.
- 구체적이며 변동성이 크다면 그 이름을 사용하지 말라
팩토리
이 규칙들을 준수하려면 변동성이 큰 구체적인 객체는 특별히 주의해서 생성해야 한다.
모든 언어에서 객체를 생성하려면 해당 객체를 구체적으로 정의한 코드에 대해 소스 코드 의존성이 발생하기 때문이다.
추상 팩토리 사용 구조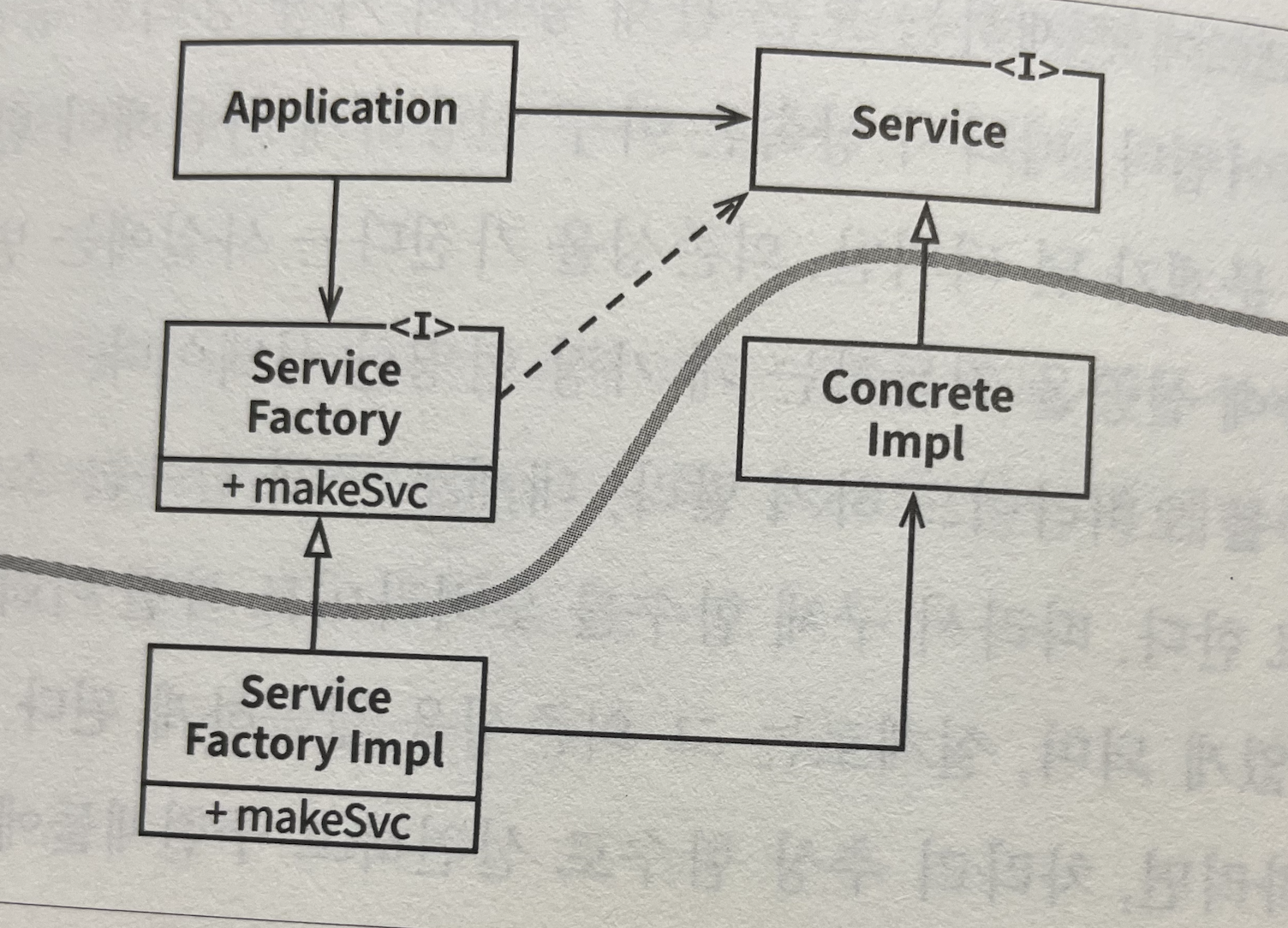
Application은 Service 인터페이스를 통해 ConcreteImpl을 사용하지만,
Application에서는 어떤 식으로든 ConcreteImpl의 인스턴스를 생성해야 한다.
ConcreteImpl에 대해 소스 코드 의존성을 만들지 않으면서 목적을 이루기 위해 Application은 ServiceFactory 인터페이스의 makeSvc 메서드를 호출한다.
이 메서드는 ServiceFactory로부터 파생된 ServiceFactoryImpl에서 구현된다.
그리고 ServiceFactoryImpl 구현체가 ConcreteImpl의 인스턴스를 생성한 후 Service 타입으로 반환한다.
곡선은 아키텍처 경계를 뜻한다. 이 곡선은 구체적인 것들로부터 추상적인 것들을 분리한다.
소스 코드 의존성은 해당 곡선과 교차할 때, 모두 한 방향, 즉 추상적인 쪽으로 향한다.
곡선은 시스템을 두 가지 컴포넌트로 분리한다. -> 추상/구체 컴포넌트
추상 컴포넌트는 애플리케이션의 모든 고수준 업무 규칙을 포함한다.
구체 컴포넌트는 업무 규칙을 다루기 위해 필요한 모든 세부사항을 포함한다.
제어 흐름은 소스 코드 의존성과는 정반대 방향으로 곡선을 가로지른다는 점에 주목하자.
구체 컴포넌트
구체 컴포넌트에슨 구체적인 의존성이 하나 있고 -> ServiceFactoryImpl 구체 클래스가 ConcreteImpl 구체 클래스에 의존
따라서 DIP에 위배된다.
하지만 DIP 위배를 모두 없앨 수는 없다.
DIP를 위배하는 클래스들은 적은 수의 구체 컴포넌트 내부로 모을 수 있고, 이를 통해 시스템의 나머지 부분과는 분리할 수 있다.
대다수의 시스템은 이러한 구체 컴포넌트를 최소한 하나는 포함할 것이다.
흔히 컴포넌트를 Main이라 부르는데, main 함수를 포함하기 때문이다.
위의 그림에서 main 함수는 ServiceFactoryImpl의 인스턴스를 생성한 후, 이 인스턴스를 ServiceFactory 타입으로 저장
그 후, Application은 이 변수를 이용해서 ServiceFactoryImpl 인스턴스에 접근할 것이다.
결론
앞으로 고수준의 아키텍처를 다루면서 DIP는 자주 나온다.
그리고 DIP는 아키텍처 다이어그램에서 가장 눈에 띄는 원칙이 될 것이다.
그리고 의존성은 위의 곡선을 경계로 더 추상적인 엔티티가 있는 쪽으로만 향한다.
'스터디 > 클린아키텍처' 카테고리의 다른 글
| [Clean Architecture] 클린 아키텍처(독립성) - 13 (0) | 2021.04.05 |
|---|---|
| [Clean Architecture] 클린 아키텍처(아키텍처란?) - 12 (0) | 2021.04.05 |
| [Clean Architecture] 클린 아키텍처(ISP : 인터페이스 분리 원칙) - 10 (0) | 2021.04.02 |
| [Clean Architecture] 클린 아키텍처(LSP - 리스코프 치환 원칙) - 9 (0) | 2021.04.01 |
| [Clean Architecture] 클린 아키텍처(OCP - 개방 폐쇄 원칙) - 8 (0) | 2021.04.01 |