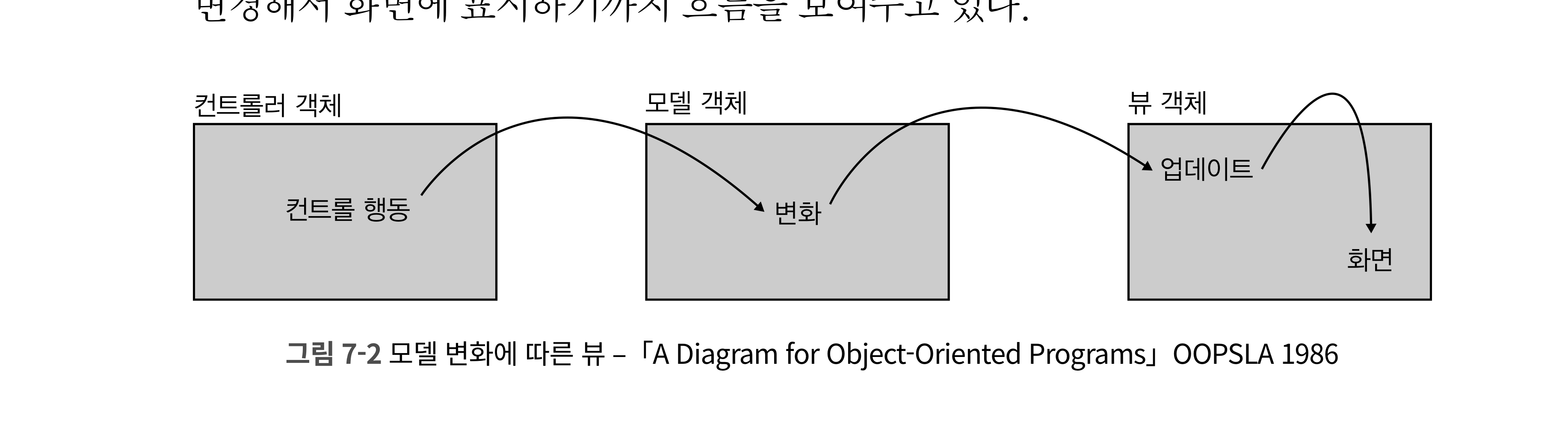
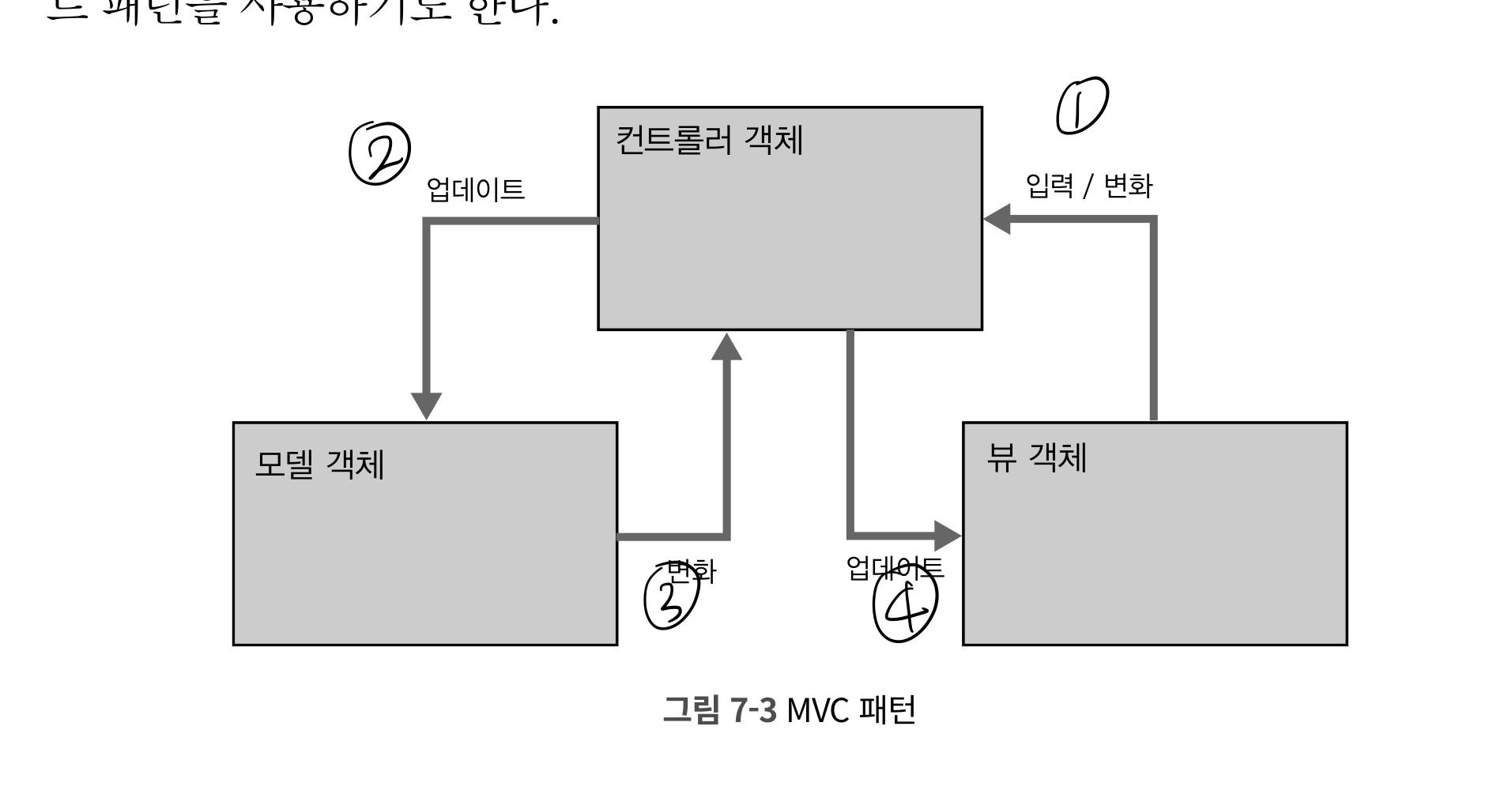
스위프트 타입 시스템
타입 시스템은 프로그래밍 언어 작성 방식과 프레임워크의 구조를 결정하는 매우 중요한 요소이다.
스위프트를 비롯한 함수 중심 언어 의 타입 시스템은 Objective-C와 코코아 프레임워크에서 사용하는 타입 시스템보다 안전하고 세밀하다.
타입 시스템
스위프트는 JS, Python처럼 Duck Type 시스템은 아니지만 명시적인 시스템이다. Objective-C 처럼 모든 객체가 Dynamic 타입은 아니지만, 프로토콜 타입을 활용하여 Dynamic하게 확장하면서도 Objective-C보다 안전하게 쓸 수 있다.
스위프트 타입
스위프트에는 크게 두 종류의 타입이 있다.
- 이름있는 타입 : Named Type
- 이름없는 타입 : Compound Type (int, char 등 Primitive Type)
합쳐진 타입은 Tuple이나 클로저/함수 타입으로 이름이 따로 정해지지 않고, 다른 타입들을 합쳐서 사용하는 타입이다. ex) (Int, (Int) -> (Int))
타입 검사
스위프트는 안전한 타입 언어를 표방한다.
"안전한 타입 언어"
값에 대한 타입을 명확하게 구분해서 사용할 수 있는 언어
컴파일러가 다른 타입으로 선언한 변수에 값을 전달하는 것을 미리 방지
컴파일 동안 안전한 타입 사용을 위해, 타입 검사를 진행한다.
타입 추론
타입 검사는 값에 대한 타입을 다르게 사용할 경우 컴파일 에러를 표시한다.
그렇다고 모든 변수를 선언할 때, 타입을 명시해야하는 것은 아니다. -> 타입 추론 덕분
func foo(x: Double) -> Int {...}
var doubleValue: Double = 3.141592
var unknown = foo(doubleValue)
func bar<T>(x: T) -> T {return x}
var floatValue: Float = -bar(1.414)코드는 스위프트 타입 추론이 양방향으로 가능하다는 것을 보여준다.
foo() 함수의 타입 정의를 보면 리턴 타입이 Int라는 것을 유추할 수 있다.
따라서 foo() 함수 리턴값을 저장하는 unknown 변수는 Int 타입이다.
bar() 함수는 제네릭 타입으로 타입이 명시되지 않았지만 floatValue 변수의 타입이 Float라서 Float 타입으로 동작한다.
스위프트 타입 검사는 기존의 Objective-C처럼 명시적으로 타입을 선언한 정보를 근거로 타입 정보를 만드는 것도 가능하다.
스위프트 타입 추론은 3단계로 진행된다.
- "제약 만들기"
- "제약 계산하기"
- "제약 판단하기"
-> 스위프트 오픈소스 TypeChecker.rst 문서를 참고
타입 변환(Type Cast)
타입 변환은 종류가 전혀 다른 타입끼리 타입을 바꾸는 것이 아니다.
비슷한 종류끼리만 타입을 바꾸는 것을 의미한다.
"타입의 종류가 같다" -> 수학에서 구조 동일성을 가지는 벡터와 좌표 시스템처럼
데이터 타입의 메모리 구조가 동일하고 다루는 소재가 다른 타입끼리만 타입을 바꿀 수 있다.
ex.1) String 과 Int 는 구조가 다른 타입이기 때문에 타입 변환이 불가능하다.
ex.2) Struct 타입이나 Class 타입에서 상속받은 객체들끼리는 구조 동일성이 유지되기 때문에 타입 변환 가능.
ex.3) 숫자를 표시하는 타입들은 구조가 동일하기 때문에 서로 전환이 가능하다. -> 다만 값에 대한 손실이 발생할 수 있는 경우에는 반드시 타입을 지정해야 한다.
의미 있는 값 vs 의미 있는 레퍼런스
"의미 있는 레퍼런스"
레퍼런스 방식으로 참조하는 대상(대부분 객체 인스턴스)이 중요하다는 것
"의미 있는 값"
값 자체가 중요하다는 것
스위프트는 의미 있는 값으로 쏠려있다.
FP에서는 함수에서 다루는 변수가 레퍼런스가 아니고 불변 변수여야만 부작용이 없다.
따라서 값 자체를 다루는 것이 더 의미 있다.
값 방식은 Reference Count를 하지 않기 때문에 그만큼 병렬 처리나 성능 최적화 측면에서 유리하다.
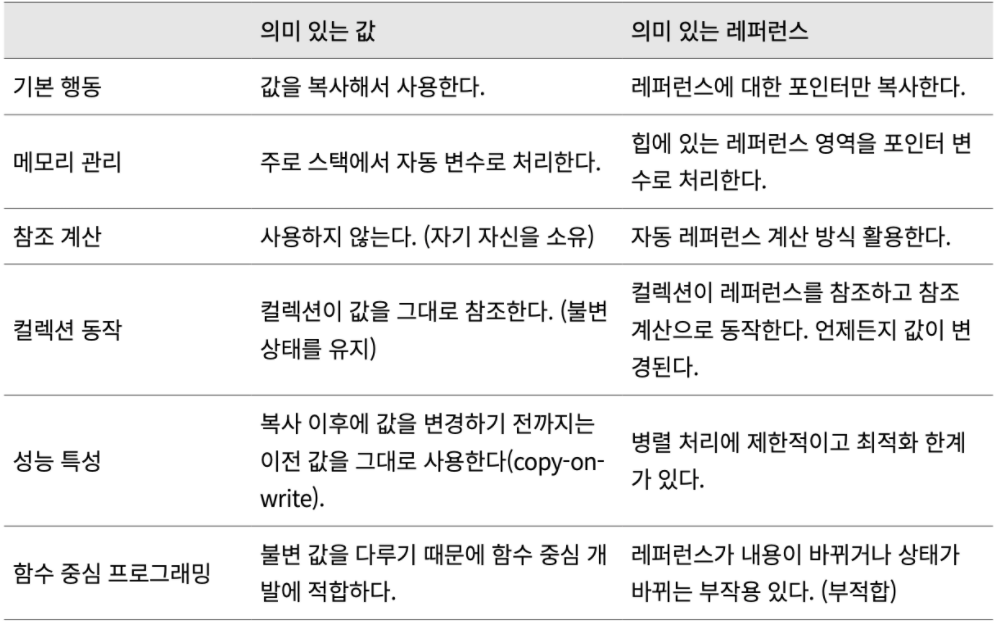
Objective-C 에서는 클래스 객체를 사용하는 경우에만 의미 있는 레퍼런스를 사용하고, C 언어와 호환하기 위한 내장 타입들은 그대로 C 언어 방식(의미 있는 값)을 사용한다.
C 언어 타입은 컬렉션에 넣지 못하기 때문에, 메모리 관리가 안되고, 타입 변환이 불편해서 객체와 함께 사용하기에 불편하다.
타입별 성능 비교
대표적인 의미 있는 값 방식 구조체 타입과 의미 있는 레퍼런스 방식 클래스 타입, 프로토콜 타입에 대해서 메모리 공간, 참조 계산, 메서드 디스패치 동작을 비교하면 표와 같다.

스택 메모리의 경우, 사용할 때 SP(스택 포인터)를 증가시키고 사용하지 않을 때 감소시키면 된다.
반면에 힙 메모리를 사용할 경우, 비어있는 힙 공간을 찾고 처리를 위한 별도의 데이터 구조가 필요다핟.
여러 스레드에 대한 안정성 확보를 위한 동작이 필요할 경우를 비교하면 힙이 상대적으로 느리다.
프로토콜 타입으로 확장하는 경우에도 세 워드(64bit 기준 24bit)보다 작은 크기 값은 스택만 사용하지만, 그보다 크면 힙 공간을 추가로 사용하기 때문에 느려질 수 있다.
정적 디스패치는 컴파일 시점에 함수의 메모리 주소를 찾아두기 때문에, 런타임에는 해당 주소로 바로 이동한다.
특정 조건에서는 컴파일러가 속도 향상을 위해 인라인에 코드를 그대로 복사하기도 한다.
반면에 동적 디스패치는 런타임에 구현 함수 목록에서 함수 메모리 주소를 찾아 이동해야 한다.
요약
- 어떤 타입을 사용할 지 결정하고, 타입에 적합한 메모리 관리 방식에 대한 고민이 프로그램 구조에 영향을 준다.
- 스위프트는 다양한 타입을 지원하기 때문에, 선택의 폭이 넓다. 그것은 개발자의 책임이 큰 것이다.
열거 타입
C 언어나 Objective-C 언어에서 열거타입(enumeration)은 단순히 정수 타입 값을 나열하는 편의를 위한 것이다.
스위프트에서는 문자열 타입도 지정가능하고, 실수 타입도 지정할 수 있다.
뿐만 아니라 모든 값이 있을 필요도 없고, 모두 다 같은 타입이 아니어도 된다.
클래스처럼 함수를 만들 수도 있고 확장도 가능하다.
열거 타입과 프로토콜
열거 타입에 정의한 값은 기본적으로 Hashable 프로토콜을 지원해야 한다.
Hashable
public protocol Hashable: Equatable {
var hashValue: Int {get}
}Hashable 프로토콜을 Equatable 프로토콜을 상속받아 만들어져서, 추가적으로 Equatable 프로토콜에 있는 == 비교 함수도 구현해야 한다.
Equatable
public protocol Equatable {
@warn_unused_result
func == (lhs: Self, rhs: Self) -> Bool
}열거 타입에서 일반적으로 동일한 타입 값을 사용하는 경우
enum PenModels{
case BallPen
case NamePen
}- 열거타입은 내부적으로 분기 처리를 하는데, 위에서부터 순서대로 비교하여 값을 할당한다.
- 자주 사용하는 case를 가장 위에 두는 것도 하나의 방법?
프로토콜 타입과 증거 테이블
클래스 타입에 대한 상속과 다형성은 가상 함수들을 런타임에 찾는 다이내믹 디스패치 방식을 사용한다.
하지만 다른 타입들은 프로토콜 중심 프로그래밍 방식에 맞춰서 프로토콜 증거 테이블을 사용해서 다형성을 구현한다.
어느 모듈의 특정 타입에 대한 프로토콜 구현 함수 이름을 프로토콜 증거 테이블에서 바로 찾아 호출할 수 있다.
ex)
protocol Drawable{
func draw()
}
struct Point: Drawable{
var x, y: Double
func draw(){...}
}
struct Line: Drawable{
var x1, y1, x2, y2: Double
func draw(){...}
}
var drawables: [Drawable]
for d in drawables{
d.draw()
}
// 출처 : https://zeddios.tistory.com/597d.draw()는 어떤 draw 메소드를 호출해야 하는가?
PWT를 사용하여 맞는 draw() 메소드 호출하게 함
변수를 포함하는 프로토콜을 컴파일하면 PWT(Protocol Withness Table)와 함께 VWT(Value Withness Table)도 만들어진다.
VWT는 의미있는 값을 가지는 타입에 대한 기본적인 동작을 다루는 생성, 복사, 파괴, 해제 함수들에 대한 참조 테이블이다.
VWT와 PWT 증거 테이블은 그림과 같이 값을 저장하는 저장소 데이터 구조를 참조한다.

값 크기가 버퍼크기보다 작으면 좌측 첫번째 구조처럼 스택공간을 그대로 저장한다.
만약 값 크기가 버퍼 크기보다 크면 좌측 두번째 구조처럼 힙에 큰 데이터 구조를 생성하고, 버퍼에는 힙 공간의 주소를 저장한다.
따라서 프로토콜 타입에서 스택만 사용하는 의미 있는 값을 사용하려면 버퍼보다 작은 데이터 구조를 사용해야 한다.
Equatable 프로토콜
Hashable 프로토콜과 마찬가지로 Hashable 프로토콜이 상속받은 Equatable 프로토콜에 대한 == 비교 함수도 동일하게 만들어진다.
== 비교 함수는 좌우에서 각각 .PenModels 파라미터를 받아서, 좌측 값에 대한 case 비교문 Int 값과 우측 값에 대한 case 비교문 Int 값을 구한다.
그리고 Int 타입의 == 비교함수를 통해서 최종적으로 같은 값인지 판단한다.
-> == 를 사용해서 enum 타입들을 비교할 때, lhs와 rhs 모두 Enum 분기처리를 통해 Int 값을 받아온 후, 가져온 Int 값을 통해 비교한다.
연관 값을 가지는 열거 타입
열거 타입에는 다른 언어에 있는 variants나 unions 형태로 여러 타입에 대한 값이 있을 수 있다.
이런 값을 열거 타입 연관 값이라고 한다.
enum PatientId{
case socialNumber(String)
case registeredNumber(Int)
}var temporaryPatient = PatientId.registeredNumber(1550)
이런 경우는 열거 타입이지만, Hashable이나 Equatable 프로토콜을 구현하는 내부 함수는 만들어지지 않는다.
왜냐하면 case 구문으로 값이 같은지 비교하지 않더라도, 특정한 값을 바로 적용하기 때문이다.
가공 없는 값을 가지는 열거 타입
열거 타입에 특정 타입을 지정해서 가공 없는 값(Raw Value)을 할당하는 방식도 흔히 사용한다.
가공 없는 값을 갖는 열거 타입의 경우는 Grade 타입처럼 열거 타입 생성자가 만들어진다.
가공 없는 값을 전달하면 열거 타입 값들과 비교한다.
열거 타입과 매칭이 되면 값이 들어가고, 매칭이 되지 않으면 null을 할당하기 떄문에 enum.Grade? 타입을 리턴한다.
특이한 점은 스택에 만든 로컬 변수를 비교할 때, == 연산 함수를 사용하지 않고 ~= 연산 함수를 사용한다는 것이다.
** ~= vs == **
~=는 범위 지정이 가능, 패턴 매칭 가능
case문에서 사용되는 것 같음
ex)
switch point{
case (0, 0): // ~= 연산자를 사용해서 패턴 매칭
return true
default:
return false
}요약
다른 언어에서 열거타입은 편의를 위해 상수를 선언하는 타입이었지만, 스위프트에서 열거타입은 패턴 매칭과 함께 확장 가능한 데이터 구조 타입이다.
열거 타입은 구조체 타입과 같이 의미 있는 값타입이다.
Optional, Process, Bit 타입등이 열거 타입의 예 이다.
구조체 타입
스위프트 표준 라이브러리는 대부분 구조체 타입을 기반으로 만들어졌다.
그만큼 구조체 타입은 스위프트에서 가장 핵심적인 타입 중 하나다.
스위프트로 프로그래밍을 한다면 클래스보다 구조체를 사용하는 것이 더 효율적이다.
구조체 타입
Q)구조체는 C언어의 구조체와 Objective-C의 클래스 중 어디에 가까울까?
struct Car {
let model = "apple"
}스위프트 구조체 타입은 클래스와 비슷하게 LifeCycle을 가지는 타입이다.
생성자인 init() 초기화 함수가 만들어진다.
그리고 model 변수 속성이 불변이기 때문에, getter 내부적으로 함수가 만들어진다
init() 함수는 구조체를 위한 메모리 박스를 할당한 다음, 내부 변수 타입인 String 타입 초기화 함수를 사용해 "apple"를 지정한다.
그리고 이 값을 model 변수 위치에 저장한다.
가변 변수가 포함된 경우
struct Car{
var driver = "tree"
}앞서 살벼본 init() 함수와 별도로 init(driver: String) 함수가 추가된다. -> 자동 생성되는 init에서 let, var인 내부 변수의 차이
driver 변수에 대한 초기값을 지정해서 객체를 초기화 할 수 있는 추가 초기화 함수를 추가해준다.
따라서
let myCar = Car(driver: "tree") 처럼 초기화 값을 넘겨 초기화 가능하다.그런데 init(driver: String) 구현이 독특하다.
구조체 타입을 초기화하기 위해 내부에서 init() 함수를 부르는 게 아니라, driver 초기 값과 함께 ㄴtruct $Car 명령을 실행하고 반환받은 값을 그대로 리턴한다.
-> 이 부분은 마치 C++ 구조체 초기화 함수처럼 구조체 내부 변수에 대한 초기값을 순서대로 전달해서 구조체 메모리를 초기화하는 방식과 비슷하다.
-> init() 함수를 부르지 않는다는 점을 기억하자
우선 driver 변수에 대한 문자열을 받아 설정하는 setter
첫번째 파라미터 변수는 자체 소유권을 갖는 문자열이고, 두번째 마라미터 변수는 inout으로 선언한 Car 구조체 변수다.
기존 Car 구조체 값이 그대로 전달되지만, 내부에서는 임시로 Car 구조체를 복사하기 위해 박스가 하나 더 만들어진다.
새로 만들어진 박스에 기존 Car 구조체를 복사하고, driver 변수에 첫 번째 파라미터 값을 할당한다.
새 박스의 값을을 두번째 파라미터 구조체인 Car에 복사하고 만들었던 박스를 메모리에서 해제한다.
함께 만들어지는 meterializeForSet() 함수는 var 변수에 대한 초기값을 바로 할당하는 경우가 아닌 경우에 사용한다.(lazy/Computed Property)
-> 개발자가 직접 호출할 수 있는 함수가 아니기에 신경 안써도 됨
구조체 타입 기반의 스위프트 타입
Int, Bool, Set, Ditionary, Array 모두 구조체로 구현됐다.
따라서 Objective-C와 다르게 스위프트는 의미 있는 값 방식으로 동작한다.
Swift 1.x 버전에는 초기 호환성을 위해 Objective-C 런타임 기반으로 동작하는 클래스 타입이 많았다.
지금은 스위프트 런타임으로 코코아 라이브러리의 상당수를 구조체 타입 기반으로 다시 작성했다.
따라서 Objective-C 기반보다 빠르다.
요약
구조체 타입은 성능 향상을 위해 대부분의 경우는 스택에 값을 할당하고 사용한다.
구조체 구조가 동적으로 변하거나 크기가 너무 크다면, 힙 공간을 예외적으로 사용하기도 한다.
힙 공간에 있는 구조체거나 글로벌 구조체의 경우 함수 범위가 벗어나도 해당 구조체를 참조할 수 있다. (참조 방식의 특징)
이런 경우 구조체는 객체에 대한 레퍼런스 방식과 비슷하게 동작하지만, 참조 계산을 사용하지 않아 순환 참조 문제가 발생하지 않는다.
'스터디 > Cocoa Internals' 카테고리의 다른 글
| [Cocoa Internals] 코코아 디자인 패턴 - 7장 (0) | 2021.08.17 |
|---|---|
| [Cocoa Internals] 불변 객체와 가변 객체 - 5장 (0) | 2021.07.28 |
| [Cocoa Internals] 객체 복사 - 4장 (0) | 2021.07.26 |
| [Cocoa Internals] 자동 메모리 관리 - 3장 (0) | 2021.07.26 |
| [Cocoa Internals] 메모리 관리 - 2장 (0) | 2021.07.11 |