여기에서 필요한 것은 다음과 같은 치환 원칙이다. S 타입의 객체 o1 각각에 대응하는 T 타입 객체 o2가 있고, T 타입을 이용해서 정의한 모든 프로그램 P에서 o2의 자리에 o1을 치환하더라도 P의 행위가 변하지 않는다면, -> S는 T의 하위 타입이다.
상속을 사용하도록 가이드
License라는 클래스가 있다고 해보자 calcFee() 메서드를 가지며 Billing Application이 메서드를 호출한다. License는 PersonalLicense와 BusinessLicense라는 두가지 '하위 타입' 을 갖는다. 두 하위 타입은 서로 다른 알고리즘을 이용해서 메서드를 오버라이드 한다.
이 설계는 LSP를 준수한다. -> Billing App의 행위가 License 하위타입중 무엇을 사용하는 지에 전혀 의존하지 않기 때문이다.
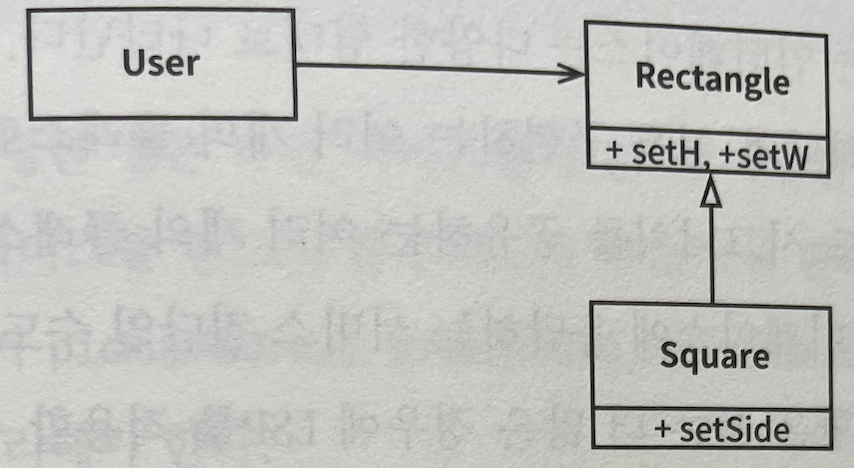
정사각형/직사각형 문제
LSP를 위반하는 전형적인 문제
Square는 Rectangle의 하위 타입으로는 적합하지 않은데, Rectangle의 높이와 너비는 서로 독립적으로 변경될 수 있는 반면, Square의 높이와 너비는 반드시 함께 변경되기 때문이다. User는 대화하고 있는 상대가 Rectangle이라고 생각하므로 혼동이 생길 수 있다.
Rectangle r = ...
r.setW(5);
r.setH(2);
assert(r.area() == 10);
...코드에서 Square를 생성한다면 assert문은 실패하게 된다. -> W든 H든 변경될 때, 정사각형은 W와 H를 모두 바꾸기 때문 이런 형태의 LSP 위반을 막기 위한 유일한 방법은 if문과 같은 조건을 이용해서 Rectangle이 실제로는 Square인지를 검사하는 메커니즘을 User에 추가하는 것이다. -> 하지만 이렇게 하면 Userdㅢ 행위가 사용하는 타입에 의존하게 되므로 타입을 서로 치환할 수 없게 된다.
LSP와 아키텍처
객체 지향이 등장한 초창기에는 LSP는 상속을 사용하도록 가이드되었다. 하지만 시간이 지나면서 LSP는 인터페이스와 구현체에도 적용되는 더 광범위하게 변했다.
여기서 말하는 인터페이스는 다양한 형태로 나타난다. 자바스러운 언어라면 인터페이스 하나와 이를 구현하는 여러개의 클래스로 구성 잘 정의된 인터페이스와 그 구현체끼리의 상호 치환 가능성에 기대는 사용자들이 존재하기 때문이다.
LSP 위배 사례
다양한 택시 파견 서비스를 통합하는 App을 만들고 있다고 가정하자.
고객은 어느 택시업체인지는 모르지만 자신의 상황에서의 적절한 택시를 찾는다.
고객이 이용할 택시를 결정하면, 시스템은 REST 서비스를 통해 선택된 택시를 고객 위치로 파견한다.
택시 파견 REST 서비스의 URI가 운전기사 DB에 저장되어 있다고 가정해보자
시스템이 고객에게 알맞은 기사흫 선택하면, 해당 기사의 레코드로부터 URI를 얻어 해당 기사를 고객 위치로 파견한다.
EX 택시기사 Bob의 파견 URI = purplecab.com/driver/Bob 시스템은 기사 URI에 정보를 붙힌다. purplecab.com/driver/Bob/pickupAddress/24 Maple St./pickupTime/153/destination/ORD
이 예제에서 분명한 것은 파견 서비스를 만들 때, 다양한 택시업체에서 동일한 REST 인터페이스를 반드시 준수하도록 만들어야 한다는 사실이다. 서로 다른 택시업체가 pickupAddress/pickupTime/destination 을 동일하게 처리해야 한다.
이제 택시업체(kakaoTaxi)에서 프로그래머를 몇 명 고용했는데, 서비스 사양서를 신중히 읽지 않았다고 가정하자. destination 필드를 dest로 축약했다. 그렇다면 파견 서비스에서는 kakaoTaxi만을 위해 모든 모듈에
개체의 행위는 확장할 수 있어야 하지만, 개체를 변경해서는 안된다. 만약, 요구사항을 살짝 확장하는 데 SW를 엄청 수저앻야 한다면, 그 SW 시스템 설계는 실패다.
SW 설계를 공부한 지 얼마 안되는 사람들은 OCP를 클래스와 모듈을 설계할 때 도움되는 원칙이라고 알고 있다. -> (나 역시... 마찬가지) 하지만 아키텍처 컴포넌트 수중에서 OCP를 고려하면 훨씬 중요한 의미를 갖는다.
사고 실험
재무제표를 Web으로 보여주는 시스템이 있다고 해보자.
표시되는 데이터는 스크롤할 수 있으며, 음수는 빨간색으로 출력한다.
보고서 형태로 변환해서 흑백 프린터로 출력해 달라고 요청
페이지마다 번호
페이지마다 머리글/꼬리글
표의 각 열에는 레이블
음수는 괄호로 묶음
새로운 코드를 작성해야 하는 것은 맞다. 하지만 SW 아키텍처가 좋다면 변경되는 코드의 양이 최소화될 것이다.
HOW?
SRP : 서로 다른 목적으로 변경되는 요소를 적절하게 분리
DIP : 요소 사이의 의존성을 체계화
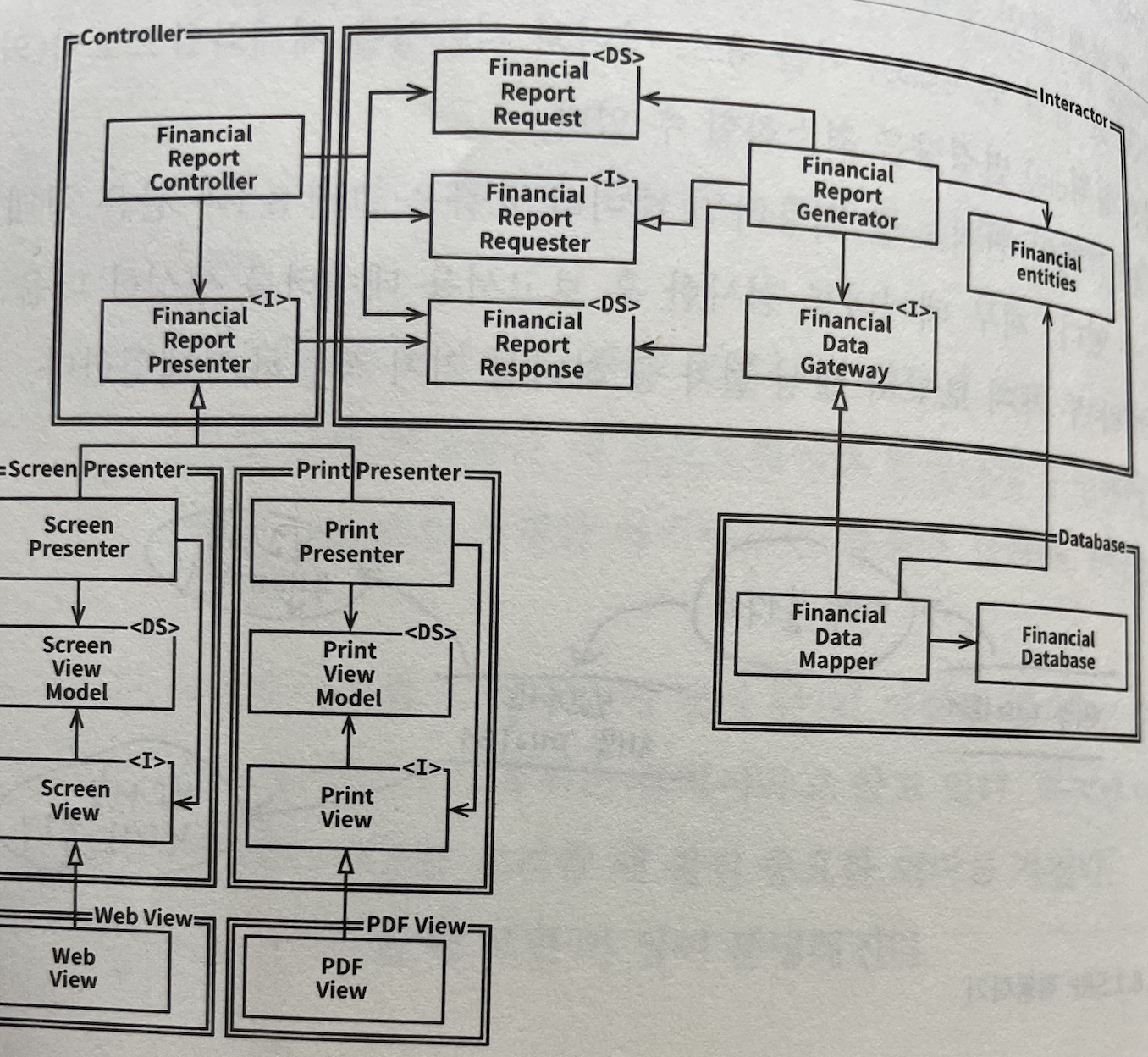
SRP를 적용하면 그림은 아래와 같다.
웹/프린트 의 책임을 분리시킨다. 이처럼 책임을 분리한다면, 두 책임 중 하나에서 변경이 발생하더라도 다른 하나는 변경되지 않도록 소스 코드 의존성을 확실히 조직화해야 한다. 또한, 새로 조직화한 구조에서는 행위가 확장될 때 변경이 발생하지 않음을 보장해야 한다.
-> 이러한 목적을 달성하려면 처리 과정을 클래스 단위로 분할하고, 이들 클래스를 컴포넌트 단위로 구분해야 한다.
열린 화살표는 사용 닫힌 화살표는 구현/상속 이다.
여기서 모든 의존성이 소스 코드 의존성을 나타낸다는 사실이다. A 클래스 -> B 클래스 라면, A 클래스에서는 B 클래스에서는 호출하지만, B 클래스는 A 클래스를 모른다.
다른 중요한 점은 이중 선은 화살표와 오직 한 방향으로만 교차한다는 사실이다.
A 컴포넌트에서 발생한 변경으로부터 B 컴포넌트를 보호하려면 반드시 A 컴포넌트가 B 컴포넌트에 의존( A -> B)해야 한다. 그림에서는 Presenter의 변경으로부터 Controller를 보호하고 View의 변경으로부터 Presenter를 보호한다. Interactor는 모든 것으로부터 보호되는데, 그 이유는 interactor가 업무 규칙을 포함하기 때문이다. Interactor = 주요 업무, 나머지 = 주변 업무
BUT, Controller는 Presenter와 View에 비해서는 중요한 업무를 한다. 마찬가지로 Presenter 또한 View 보다는 더 중요한 업무를 한다. -> 이것이 바로 아키텝처 수준에서 OCP가 동작하는 방식이다. 아키텍트는 HOW, WHY, WHEN 발생하는지에 따라서 기능을 분리하고, 분리한 기능을 컴포넌트의 계층구조로 조직화한다. 컴포넌트를 계층구조로 조직화하므로써 저수준 컴포넌트에서 발생한 변경으로부터 고수준 컴포넌트를 보호할 수 있다.
방향성 제어
IF) FinancialDataGateway 인터페이스는 FinancialReportGenerator와 FinancialDataMapper 사이에 위치하는데, 이는 의존성을 역전시키기 위해서다 만약, FinancialDataGateway 인터페이스가 없었다면, 의존성은 Interactor 컴포넌트에서 DB 컴포넌트로 바로 향하게 된다. FinancialReportPresenter 인터페이스와 2개의 View 인터페이스도 같은 목적을 갖는다.
정보 은닉
FinancialReportRequester 인퍼테이스는 방향성 제어와는 다른 목적을 가진다. 이 인터페이스는 FinancialReportController가 Interactor 내부에 대해 너무 많이 알지 못하도록 막기 위한 목적을 갖는다. 만약 이 인터페이스가 없었다면 Controller는 FinancialEntities에 대해 추이 종속성을 가지게 된다.
추이 종속성 - A 클래스가 B 클래스에 의존하고, B 클래스가 C 클래스에 의존한다면 -> A 클래스는 C 클래스에 의존하게 된다.
추이 종속성을 가지면, SW 엔티티는 '자신이 직접 사용하지 않는 요소에는 절대 의존해서는 안된다.'라는 원칙을 위반한다. -> 이 원칙은 ISP와 CRP를 설명할 때 다시 설명한다.
다시 말해, Controller에서 발생한 변경으로부터 Interactor를 보호하는 일의 우선순위가 가장 높지만, 반대로 Interactor에서 발생한 변경으로부터 Controller도 보호되기를 바란다. 이를 위해 Interactor 내부를 은닉한다.
결론
OCP는 시스템의 아키텍처를 떠받치는 원동력 중 하나다. OCP의 목표는 시스템을 확장하기 쉬운 동시에, 변경으로 인해 너무 많은 영향을 받지 않도록 함에 있다. 이러한 목표를 달성하려면 시스템을 컴포넌트 단위로 분리하고, 저수준 컴포넌트에서 발생한 변경으로부터 고수준 컴포넌트를 보호할 수 있는 형태의 의존성 계층구조가 만들어져야 한다.
좋은 SW 시스템은 깔끔한 코드로부터 시작한다. 좋은 벽돌을 사용하지 않으면 아키텍처가 좋고 나쁨은 중요치 않다. 반대로 좋은 벽돌을 사용하더라도 엉망으로 만들 수 있다.
-> 따라서 좋은 벽돌로 좋은 아키텍처를 정의하는 원칙이 필요한데... 그것이 SOLID이다.
SOLID 원칙은 함수와 데이터 구조를 클래스로 배치하는 방법 그리고 이들 클래스를 서로 결합하는 방법을 설명해준다.
SOLID의 목적
변경에 유연하다
이해하기 쉽다
많은 SW 시스템에 사용할 수 있는 컴포넌트의 기반이 된다.
'중간 수준'이라 함은 프로그래머가 이들 원칙을 모듈 수준에서 작업할 때 적용할 수 있다는 뜻이다.
SRP
단일 책임 원칙 이름만 들으면 모든 모듈이 단 하나의 일만 해야 한다는 의미로 받아들이기 쉽다. -> 함수는 하나의 일만 해야 한다 가 정확하다.
모듈 = "소스 파일"
원칙을 위반하는 징후
우발적 중복
급여 App의 Employee Class 해당 클래스는 calculatePay(), reportHours(), save() 메서드를 갖는다.
calculatePay() 는 회계팀에서 기능을 정의하며, DFO 보고를 위해 사용
reportHours() 는 인사팀에서 기능을 정의하고 사용하며, COO 보고를 위해 사용
save() 는 DBA가 기능을 정의하고, CTO 보고를 위해 사용
각각의 메서드를 갖고 있는 Employee라는 단일 클래스에 3종류의 actor가 결합되었다.
예를 들어, calculatePay()와 ㄱeportHours()가 초과근무를 제외한 업무 시간을 계산하는 알고리즘을 공유한다고 해보자 그리고 중복을 회피하기 위해 regularHours()라는 메서드를 넣었다고 가정하자
이제 CFO 팀에서 초과 근무를 제외한 업무 시간을 계산하는 방식을 수정하기로 했다. 반면 인사를 담당하는 COO 팀에서는 초과 근무를 제외한 업무 시간을 CFO 팀과는 다른 목적으로 사용하기에, 변경을 원치 않는다.
해당 업무를 받은 개발자는 calculatePay() 메서드가 regularHours()를 호출한다는 것을 발견!
하지만 reportHours() 메서드에서도 호출된다는 것을 발견하지 못함..
개발자는 업무를 테스트하고 변경했다. CFO 팀에서는 기능을 검증하고 시스템은 배포된다. 하지만 COO 팀에서는 이러한 사실을 알지 못했고, reportHours() 메서드를 사용하고 나서야 잘못된 수치들을 확인한다.
-> 누가, 어떤 목적으로 사용하는지에 대한 기능을 제공을 단일로 책임? , 즉 Class가 단일 actor에 대한 책임을 진다?
병합
소스 파일에 다양하고 많은 메서드를 포함하면 병합이 자주 발생할 것이다. 이들 메서드가 서로 다른 actor를 책임진다면 병합이 발생할 가능성은 더 높다
DBA가 속한 CTO팀에서 DB의 Employee Table Schema를 수정하기로 했다. 동시에 COO 팀에서는 reportHours() 메서드의 보고서 포맷을 변경하기로 했다.
서로 다른 개발자가 Employee Class를 체크아웃 받을 후 적용할 것이다. 이러한 변경사항들은 분명히 충돌한다.
-> 이 문제를 벗어나기 위해서는 서로 다른 actor를 책임지는 코드를 서로 분리하는 것이다.
해결책
가장 확실한 해결책은 데이터와 메서드를 분리하는 방식이다. 즉, 아무런 메서드가 없는 간단한 데이터 구조인 EmployeeData Class를 만들어 세개의 Class가 공유한다. 각 클래스는 자신의 메서드에 반드시 필요한 소스 코드만을 포함한다. 각 클래스는 서로의 존재를 모른다.
하지만 개발자가 3가지 Class를 인스턴스화하고 추적해야 한다는 게 단점이다. 이러한 난관을 피하기 위해 퍼싸드 패턴을 사용한다.
EmployeeFacade에 코드는 거의 없다. 이 클래스는 3개의 클래스의 객체를 생성하고, 요청된 메서드를 가지는 객체로 위임하는 일을 책임진다.
결론
SRP는 메서드와 클래스 수준의 원칙이다. 하지만 이보다 상위 두 수준에서도 다른 형태로 다시 등장한다. 컴포넌트 수준에서는 공통 폐쇄 원칙 아키텍처 수준에서는 아키텍처 경계의 생성을 책임지는 변경의 축이 된다.